Pytorch DataLoader 加速
问题
在训练机器学习作业的 ResNet 网络时,发现每一个 epoch 之前都会卡上十几二十秒才开始 模型真正的训练。具体表现如下:
- 每个 epoch 的 tqdm 进度条之间要卡十几秒才会出现

- 显卡占用率时高时低,没有全力干活

原因
一句话概括,是每个 epoch 前数据读取到内存再到显存占用了绝大部分时间。
看下面两张图,时间都花到读数据了,显卡基本全程摸鱼。
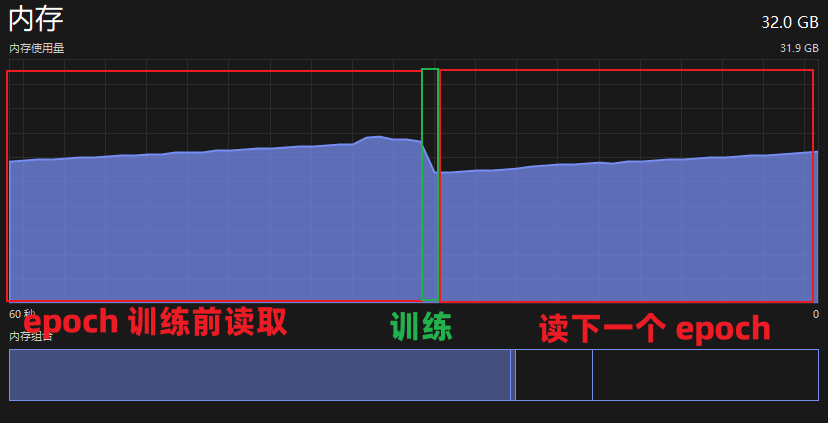

详细来说,在每个 epoch 开始之前,dataloader 从传入的 dataset 中通过 getitem,将初始化时准备好的数据返回。
class MyDataset(Dataset):
...
def __getitem__(self, idx):
image = self.images[idx]
label = self.labels[idx]
if self.transform:
image = self.transform(image)
return image, label
而且,这里 transform 将图像转换成 tensor 也花了不少时间。这种与数据增强无关的 transform 显然可以提前处理好。但这里每次读取都要 transform 一遍,很浪费。
再来看 dataloader:
trainLoader = Data.DataLoader(trainSet, batch_size=batch_size, shuffle=True, num_workers=16, drop_last=True)
windows 上设置 num_workers 不为 0 时会让数据提供给 cpu,也就是到内存里去。这样我们 getitem 返回的数据又被拷贝了一份。
然后,在 epoch 中的训练里经过如下代码:
for batch, (x, y) in loop:
x, y = x.cuda(), y.cuda()
...
内存里的数据又要拷到显存里,我们训练才得以正式开始。
前前后后,一份数据被拷贝了三回啊三回。训练能不慢吗。
解决
小试牛刀
把 dataloader 的 num_worker 设置为 0。直接将内存的数据拷到显存。这样已经能基本解决问题了。
更快
如果数据集如果不是太大,并且显存没有到捉襟见肘的地步时,提前将数据集读入显存显然是最省时的方案。
先修改 dataset 类,在初始化的时候就进行一部分的 transform 以及读入显存。
class MyDataset(Dataset):
...
def __init__(..., pre_transform=None, ...):
self.all_data = []
self.all_label = []
...
foreach:
data = ...
label = ...
if pre_transform:
data = pre_transform(data)
data = torch.tensor(data)
self.all_data.append(data)
self.all_label.append(label)
...
self.all_data = torch.stack(self.all_data).cuda()
self.all_label = torch.tensor(self.all_label).cuda()