SE-ML05-K 邻近
k-NN 分类器
算法流程
对测试样本,找训练样本中最近的 $k$ 个,这 $k$ 个样本中标签最多的就是测试样本的类。
k 的取值
- k 一般取奇数值,避免平局
- k 取不同的值,分类结果可能不同
- k 值较小时,对噪声敏感,整体模型变得复杂,容易过拟合
- k 值较大时,对噪声不敏感,整体模型变得简单,容易欠拟合
变种
最邻近分类器
k-NN 的 $k=1$ 的特殊情况。
泛化错误率,不超过贝叶斯分类器错误率的两倍。
k-NN 回归
算法流程
对测试样本,找训练样本中最近的 $k$ 个,将这 $k$ 个样本的标签加权平均得到预测值。
近邻平滑
- 二次核
- 次方核
- 高斯核
降低近邻计算
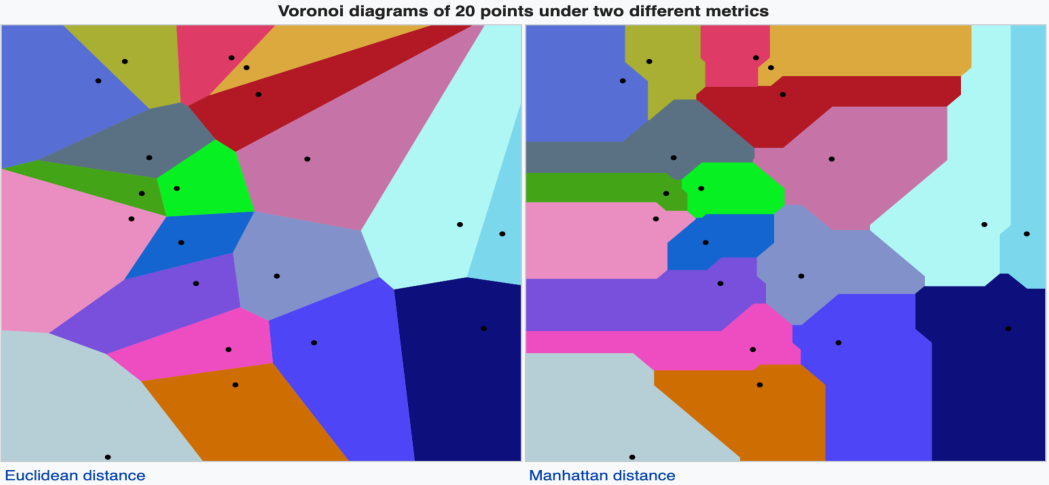
维诺图
就是类别预测图,根据决策边界,将边界内填色。
KD-Tree
OI-wiki 讲得更好一点。
- 选择维度,标准是方差
- 选择切割点,可以选第一步选择的维度中,为中位数的点
- 切割点作为当前根节点,切割的两个空间作为左右子树
- 递归。直到当前空间只有一个点