读论文-Vectorized Batch PIR
传统的 PIR (Private Information Retrieval) 里,客户端一次 PIR 只会请求数据库中的一个项。但在实际使用中,客户端往往会请求多个项,但为每一个项都单独调用一次 PIR 显然不够并行,而且会暴露用户请求的次数,所以诞生了 Batch PIR。这篇论文提出了一个基于向量化优化的 Batch PIR。相较传统的 Batch PIR,沟通开销有 7.5x ~ 98.5x 的提升。
前置知识
- Somewhat Homomorphic Encryption
- Vectorized Homomorphic Encryption
- Noise Growth and Computation Cost of SHE Operations
- PIR and Batch PIR
Previous Batch PIR
Angel 等人的传统 PIR 方法
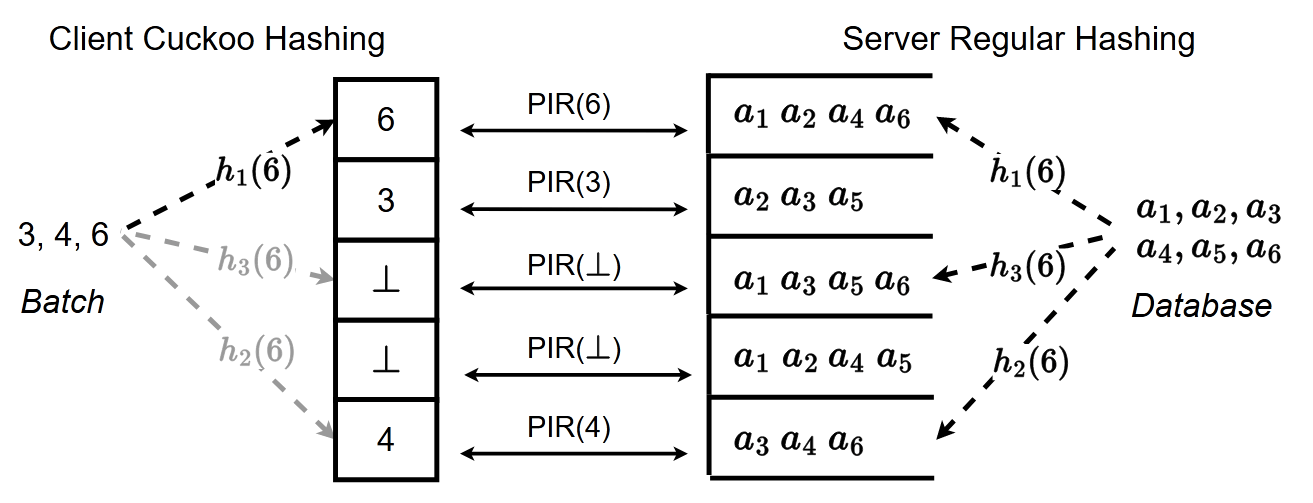
以论文里的图为例:
在所有请求发生之前,server 需要初始化 $w$ 个哈希函数 $h$(图中 $w=3$ 个)。然后将数据库中的每一项的项数编号,分布通过这几个函数来映射到 $w$ 个桶里。
桶的大小一般取 $B=1.5b$,其中 $b$ 是客户端请求 batch 的宽度。图中 $b=3, B=5$
客户端发起请求,目标是生成一个宽度为 $B$ 的请求向量。对客户端请求的 batch 中的每一项,依次尝试使用那几个哈希函数来映射到桶里,只要有一个能映射到空桶(图中用 $\perp$ 表示),就把这一项放进去。
当然,也有可能所有哈希映射到的桶都发生冲突了。这时,直接将当前项插入到某个冲突的桶,桶里原来的项拿出来再尝试能不能重新插回去(试一试其他哈希得到的位置,还不行就一直搜索下去)。这样搜索一定次数还是没找到合适的位置时,宣告失败。
失败的情况在论文的 Section IV-E 中讨论。暂时还没去看。
生成好请求向量后,这个向量里的每一个分量都要执行一次 PIR。最终得到结果。
而对于每一个 PIR instance,客户端需要知道当前请求的项在服务端桶里是多少项。解决方法很多,一种是客户端提前获取这个 mapping 规则。
这个方法的本质是将数据库分块,以便同时发起多个 PIR。缺点是通信开销很大。因为实际发送的内容是密文,而 Angel 提出的这个方法中,对每一个 PIR instance 都有一个相当大的密文(21 KB - 128 KB)。如果 batch 大一点,通信吞吐量要取到 MB 级别,差不多是明文的 215x 了。
Warm up protocol
Warm up 协议实现了一个非 Batch 的 PIR,同时将请求与回复向量化。
本质是升维。将数据库的一维线性访问变成三维。相应地,客户端的请求也要变成三个维度。为了向量化,客户端请求进行了 one-hot 编码。