Asst1
Prog1-mandelbrot_threads
使用 std::thread 来绘制分形图像。
默认策略
默认策略是将图像分成高度相同的几块,每一块分给一个线程画。
这样其实做不到负载均衡,因为每一块画的工作量是不同的。
特别是 view1,很明显发现画中间部分的线程工作时间远高于两边的线程。
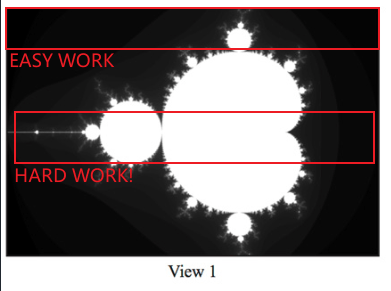
代码实现很朴实,均分然后画就好了。
在 R7 5800x上(原生 8 核心 16 线程),画 view1:
- 8 线程倍率:4.04x
- 16线程倍率:7.55x
都被 view1 中的画中间部分的线程拖后腿了。
int startRow = args->height / args->numThreads * args->threadId,
numRows = args->height / args->numThreads;
mandelbrotSerial(
args->x0, args->y0,
args->x1, args->y1,
args->width, args->height,
startRow, numRows,
args->maxIterations,
args->output
);
均衡策略
让线程按行交错绘制图像。
其实这个策略是在模拟随机分配任务。思想是将任务分成尽可能小的部分,然后让大家随机挑任务做。
可以证明对长度为 $n$ 的数列 $a$(工作量),在其中随机取 $n/s$ 项($s$就是线程数),其和的期望是相同的。
代码实现是按行交错绘制,实现起来比较简单。
对于 view1:
- 8 线程:7.53x
- 16 线程: 11.48x
16线程反而缩水得很严重,主要原因应该是 8 线程时每个线程独享一个核心,基本做到了并行。但是 16 线程时就是两个线程争抢一个核心了,需要并发。
int totHeight = args->height;
for(int line = args->threadId; line < totHeight; line += args->numThreads) {
mandelbrotSerial(
args->x0, args->y0,
args->x1, args->y1,
args->width, args->height,
line, 1,
args->maxIterations,
args->output
);
}
核心与线程
问 ChatGPT 得知,CPU 中核心和线程大概是这样的:
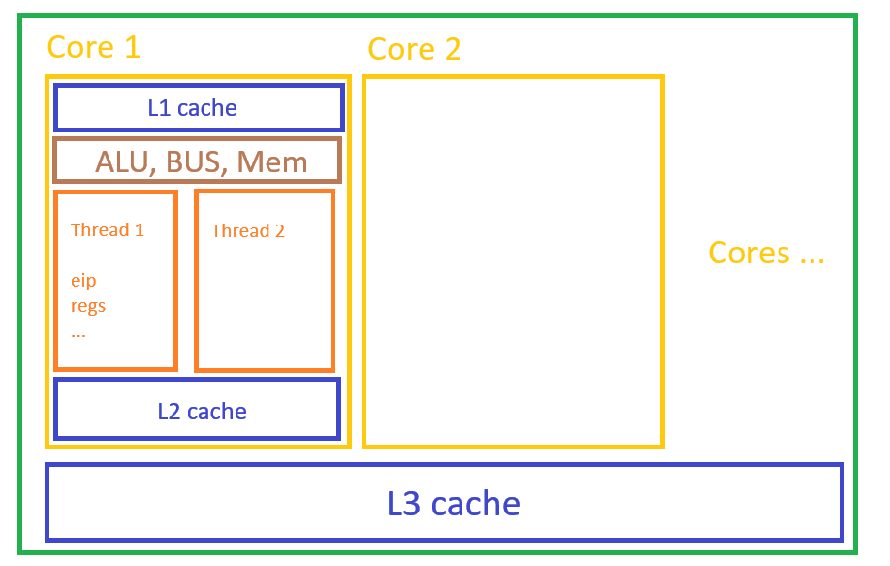
但也存在少量架构中线程有独立的 L1 cache。
从高层次往低层次:
系统级线程 - 逻辑处理器 - 物理内核
Prog2-vecintrin
找不到当时写的代码了,之后再来重新补
总之,这个代码任务介绍了 SIMD。
Prog3-mandelbrot_ispc
ISPC 在 VSCode 中的配置
这部分作业我挪到 WSL 上面做了,因为我的 Linux 机子处理器没有 AVX2 指令集。ISPC 只能在有这个指令集的机器上做。
首先得保证有 ISPC 编译环境。
然后,在 VSCode 上写 ISPC,要安装 ISPC 扩展。
吐槽这个扩展:一旦你的 ISPC 代码有 error,vscode 的 output 就会强制跳出来,ispc 的 language server 的 log 在其中疯狂刷新,很影响注意力
这个扩展还要求安装 C# 环境。

Download - Stable | Mono 按网页里的引导来配就行。Ubuntu 上一通 apt 就装好哩。
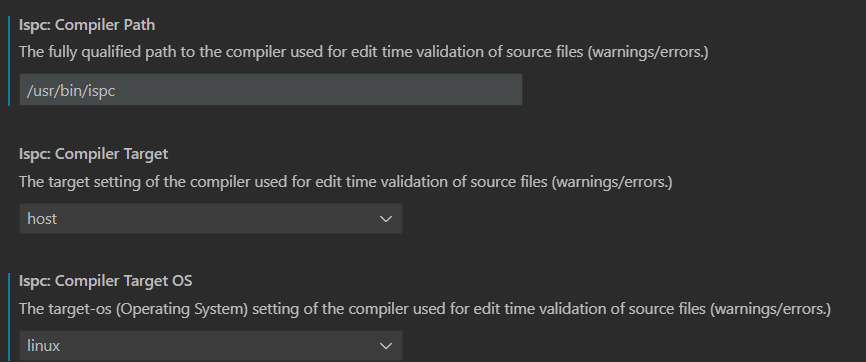
最后,在 ISPC 插件设置中配置平台与 ISPC 编译器路径即可。我只改了蓝色的这两项,改完重启下 VSCode,插件就可以正常工作了。
ISPC 基础
正式介绍 —— ISPC。
实验文档说,ISPC 程序的每一个实例都是在 SIMD 单元里并行执行的。每一个实例都有两个隐含的变量:programIndex 和 programCount。前者是此实例的序号,后者是实例数。
对于一个求向量和的代码:
const int TOTAL_VALUES = 1024;
float a[TOTAL_VALUES];
float b[TOTAL_VALUES];
float c[TOTAL_VALUES]
for(int i = 0; i < TOTAL_VALUES; i++)
c[i] = a[i] + b[i];
对应 ISPC 代码:
export sum1(uniform int N, uniform float* a, uniform float* b, uniform float* c) {
for(int i = 0; i < N; i+= programCount) {
c[programIndex + i] = a[programIndex + i] + b[programIndex + i];
}
}
export 使这个函数能直接被 C/C++ 代码调用 uniform 标识的参数表示对所有实例都相同
可以看到,每个实例负责相邻的 N 个分量的求和。
但是,ISPC 并不希望你详细到指定每个实例干什么工作。不该以“每个实例负责相邻的 N 个分量的和” 设计程序,而是以“求和的工作可以分解成每个分量求和的工作” 来设计程序。如下:
export sum2(uniform int N, uniform float* a, uniform float* b, uniform float* c) {
foreach (i = 0 ... N) {
c[i] = a[i] + b[i];
}
}
通过 ISPC 的 foreach 来实现。
大任务分解成每个分量求和的小任务时,这些小任务之间是互不影响的,所以执行的顺序也没有要求。我们在 sum1 中将相邻的分量放在一个实例中求和因此没有任何必要。所以通过 foreach 让 ISPC 自己决定小任务执行的顺序就行,程序会变得简洁一些。
Part 1
运行一下分形的 ISPC 函数。和 Prog 1 类似,下面结果是第一个 view 的结果。
[mandelbrot serial]: [143.721] ms
Wrote image file mandelbrot-serial.ppm
[mandelbrot ispc]: [24.609] ms
Wrote image file mandelbrot-ispc.ppm
(5.84x speedup from ISPC)
可以看到,我们使用了 8 宽度的 SIMD 指令,但远没达到 8 倍的加速比。
需要注意的是,这里的 ISPC 是通过 SIMD,在一个核心上使用 AVX2 指令集发射 8-宽度的指令来实现的并行(线程)。而 Prog 1 是通过多线程(比如 8 个线程)来实现的并行(一个线程上只有一条数据流)。二者有本质区别。
怀疑遇到了和 Prog1 中一样的问题。所以手动将 foreach 改写成交替计算,发现没有任何提升。除此之外,将 output 的赋值删掉,即去掉内存访问,还是没有提升。
可能原因是具体负责计算的函数 mandel 内部有些计算不便用 SIMD 实现,难以向量化。所以用 ISPC 达不到向量宽度的加速比。
通过询问 GPT,可能是 mandel 内部的 if (z_re * z_re + z_im * z_im > 4.f) 语句会导致不同的数据流执行路径发生改变而变得不一致,从而无法向量化。
要验证这个猜想,可以在 ispc 编译命令中加入 --emit-asm 查看汇编代码。mandel 的汇编被打散成了很多截,开了 O0 可读性也还是比较差。我只能暂时偷懒地接受这个猜想了😭👊。
Part 2
Part 1 里是在一个核心上使用 SIMD 完成任务。而 ISPC 提供了 task 机制来支持多个核心上的并行。这个并行是线程级的,你可以创造超过核心数量的 task。
export void foo_withtasks()
{
// create tasks
launch[task_count] foo_task();
}
在绘制分形图像任务上,发射两个 task。
[mandelbrot serial]: [143.648] ms
Wrote image file mandelbrot-serial.ppm
[mandelbrot ispc]: [24.644] ms
Wrote image file mandelbrot-ispc.ppm
[mandelbrot multicore ispc]: [12.497] ms
Wrote image file mandelbrot-task-ispc.ppm
(5.83x speedup from ISPC)
(11.49x speedup from task ISPC)
可以看到,基本达到了 2x 的加速比。这个并行效果还真不错哩。
我这里任务数量到 4 以后,加速比就没有提升了。我给 WSL 分了 8 个 processors,可能程序只能完全利用 4 个 processors。
Hardware thread V.S. ISPC task 高层视角(API 调用视角)上,二者是基本一致的,只是线程的开销会稍微大一点。(参考 Prog1 中 8 线程带来了 7.5x 的加速,而 Prog3 中 2 任务带来了 11.49 / 5.83 = 1.97x 的加速); 底层视角(硬件实现)上,ISPC task 根据 ISPC 任务特点(SIMD)做了优化,并且由 ISPC 运行时管理与调度,性能稍好。
Prog4- sqrt
这个任务是将一个向量的每一个分量开根。使用牛顿法迭代。
Task1
运行一下 sqrt 的代码。
[sqrt serial]: [613.685] ms
[sqrt ispc]: [127.356] ms
[sqrt task ispc]: [9.783] ms
(4.82x speedup from ISPC)
(62.73x speedup from task ISPC)
和 prog3 类似,ISPC 理论 8 倍加速和 task 的 threads * 8 倍加速都没达到。应该也是负载均衡的问题。我们在 task2 里继续探索。
Task2
任务2要求通过修改输入的 value 数组,来实现最大的和最小的加速比。
在这个并行任务中,最大的两个开销是 (1) 运算开销 和 (2) 调度开销。前者占比越大加速比越大。后者为 0 时基本可以达到理论加速比。
根据文档里的 convergence 迭代次数图,1 是迭代次数(代表了运算开销)最少的,而 3 是迭代次数最多的。所以value 数组设置为 1 和 2.999,可以分别实现运算开销占比最大化和最小化。
设置为 1:
[sqrt serial]: [10.802] ms
[sqrt ispc]: [5.868] ms
[sqrt task ispc]: [6.237] ms
(1.84x speedup from ISPC)
(1.73x speedup from task ISPC)
可以看到,加速比小了很多。开了 task 之后,效率反而下降了。这很正常,因为线程调度开始花时间了。
设置为 2.999:
[sqrt serial]: [1306.762] ms
[sqrt ispc]: [188.561] ms
[sqrt task ispc]: [15.588] ms
(6.93x speedup from ISPC)
(83.83x speedup from task ISPC)
计算开销变大后,CPU 主要精力就能花在正道上了。所以加速比自然增大到了一个合理的值。